

Mejora la simulación con la última tecnología HPC basada en GPU
La necesidad de simulación y análisis más rápidos, más frecuentes y más complejos en ingeniería está superando rápidamente la cantidad de capacidad informática disponible en muchas organizaciones. En Ansys, hemos aprovechado la computación de alto rendimiento (HPC) en las áreas de computación paralela, paramétrica y en la nube en un esfuerzo por ayudar a nuestros clientes a satisfacer la necesidad de simulaciones avanzadas y mayores recursos informáticos.
La compatibilidad con la aceleración de la unidad de procesamiento de gráficos (GPU) también ha ayudado a mejorar el rendimiento de la simulación, y recientemente anunciamos que Ansys Mechanical es uno de los primeros productos de análisis de elementos finitos (FEA) compatible con los nuevos aceleradores de la serie AMD Instinct™ MI200, el centro de datos de AMD. -GPU de clase.

Ansys y AMD colaboraron estrechamente para permitir que Mechanical sea compatible con estas GPU. De acuerdo con las pruebas de Ansys, los usuarios pueden experimentar aceleraciones entre 3X y 6X en modelos mecánicos estructurales grandes utilizando el solucionador directo disperso en las aplicaciones de Ansys Mechanical.
La compatibilidad con los aceleradores AMD Instinct brinda a los clientes de Ansys más flexibilidad al elegir hardware HPC, tanto en las instalaciones como en la nube. Con la capacidad de ejecutar simulaciones complejas más rápido, los usuarios podrán mejorar la calidad de los resultados de sus simulaciones y, al mismo tiempo, reducir el tiempo de comercialización.
HPC+GPU equivale a un rendimiento sin igual
Esta convergencia de recursos de HPC y la potente aceleración de la GPU pueden desbloquear potentes mejoras de rendimiento para nuestros clientes de Ansys Mechanical.
HPC ya permite a los usuarios de FEA aumentar la fidelidad de sus simulaciones, analizar ensamblajes completos, realizar más análisis no lineales, evaluar más posibilidades de diseño y realizar estudios de optimización a gran escala. En otras palabras, un análisis más rápido, mejores diseños y un tiempo de comercialización más rápido con menos reelaboración. La combinación de potentes recursos informáticos y licencias Ansys HPC puede ayudar a nuestros clientes a crear mejores productos más rápido.
La aceleración de GPU es otro elemento clave para mejorar el rendimiento de la simulación. Al habilitar el soporte de GPU para ciertos procesos, podemos acelerar las simulaciones mientras mantenemos la precisión de los resultados.
Los aceleradores de la serie AMD Instinct MI200 se basan en la nueva arquitectura AMD CDNA™ 2, que fue diseñada para admitir aplicaciones exigentes de computación científica y aprendizaje automático. Para admitir los aceleradores AMD Instinct, Ansys desarrolló un código en Mechanical para interactuar con las bibliotecas AMD ROCm™ en Linux para admitir el rendimiento y la escalabilidad en los aceleradores AMD.
Hemos mejorado de forma constante y continua el rendimiento de Mechanical en los recursos de HPC y la capacidad de aprovechar la aceleración de la GPU. Al admitir los aceleradores AMD Instinct™ MI200 Series en Ansys Mechanical 2022 R2, los clientes pueden experimentar aceleraciones significativas según el modelo y las propiedades de la matriz utilizando estas GPU AMD Instinct con nuestros solucionadores directos.
En un ejemplo, Ansys pudo mostrar aceleraciones de hasta 8x con una GPU AMD y 14x con dos GPU AMD para analizar un modelo de bloque de motor con 4,2 millones de grados de libertad (análisis estático no lineal que implica contacto, plasticidad y elementos de junta) en un clúster de Linux.
También anunciamos la compatibilidad con el paralelismo híbrido en Mechanical, que combina el modelo paralelo de memoria distribuida (DMP) con el modelo de memoria compartida (SMP). Esto brinda a los usuarios la flexibilidad para maximizar el rendimiento en las estaciones de trabajo y en los clústeres. El paralelismo híbrido reduce los requisitos de memoria de DMP y elimina las restricciones de clúster de SMP. Los usuarios pueden ejecutar trabajos más grandes en su hardware y aprovechar más núcleos en un clúster para mejorar la escalabilidad paralela de sus simulaciones.
You May Also Like

Ansys Discovery | Usando Block Recording para parametrizar un modelo 3D en Discovery Modelling
La parametrización de un modelo 3D puede resultar muy útil para estudiar distintas configuraciones
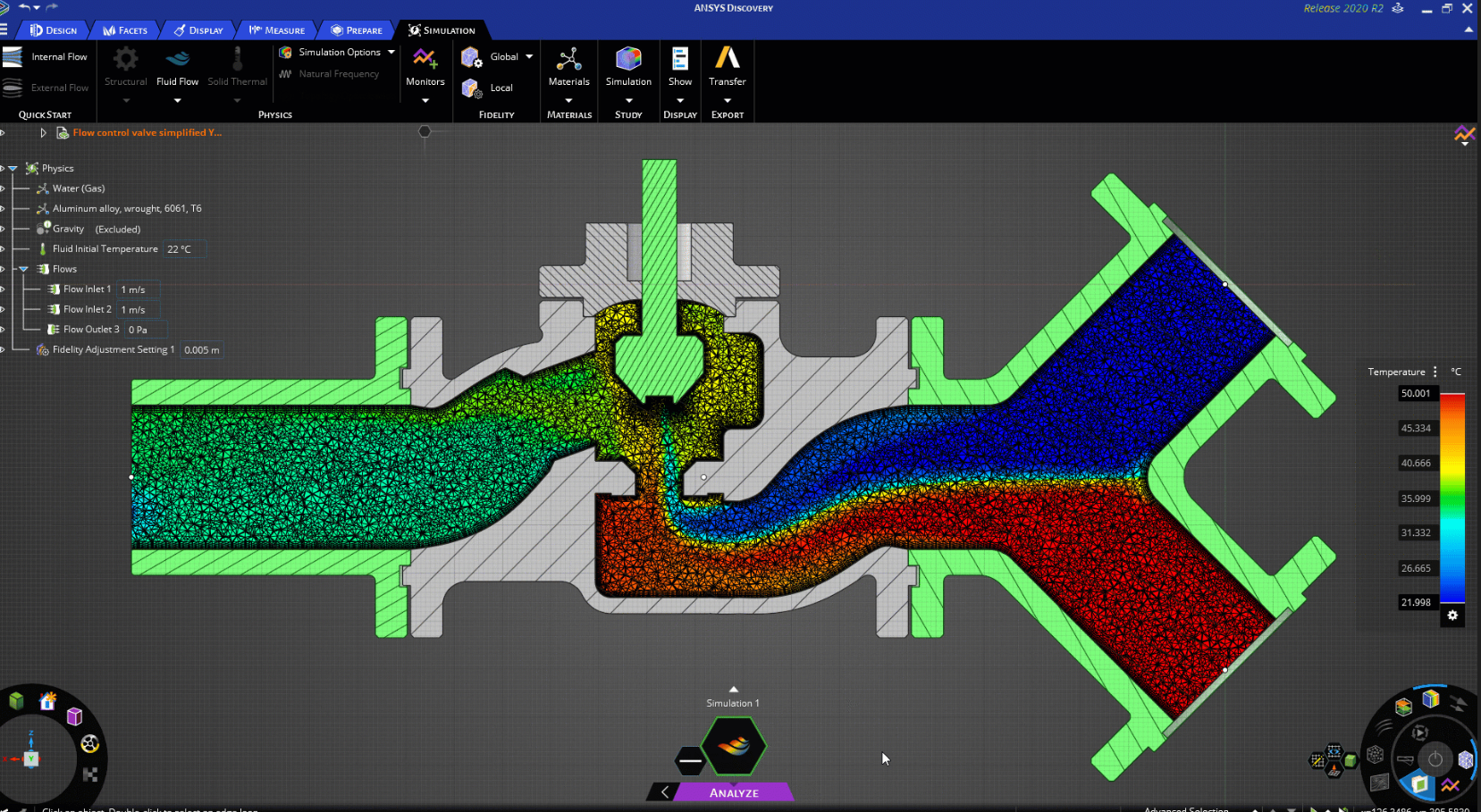
Reduce costes en pruebas físicas garantizando la eficiencia de la válvula de control mediante la simulación
La simulación desempeña un papel clave en el diseño de una válvula de control con una capacidad

NX CAD | Creación y gestión de unidades
Muchas veces necesitamos que nuestras medidas se tomen en una determinada unidad, así nos ahorramos